
Hi, I'm thinkthinking, and I build ZenMux.ai.
After our last study — where we spent $1,000 asking 27 models from 16 providers "Who are you?" 29,700 times — we just launched a new research project: Token Economics, and the phenomenon we're calling the DeepSeek Kill Line.
This post starts with a simple question that gets more interesting the longer you think about it:
If we stripped away pricing as a differentiator, which model would developers actually choose?
The Spark: DeepSeek V4 Pro Breaks Through
It all started after DeepSeek V4 Pro launched. On ZenMux, we watched something very clear happen:
DeepSeek V4 Pro's usage climbed fast — at one point, it even matched and briefly surpassed Claude's flagship Opus 4.8 in call volume.
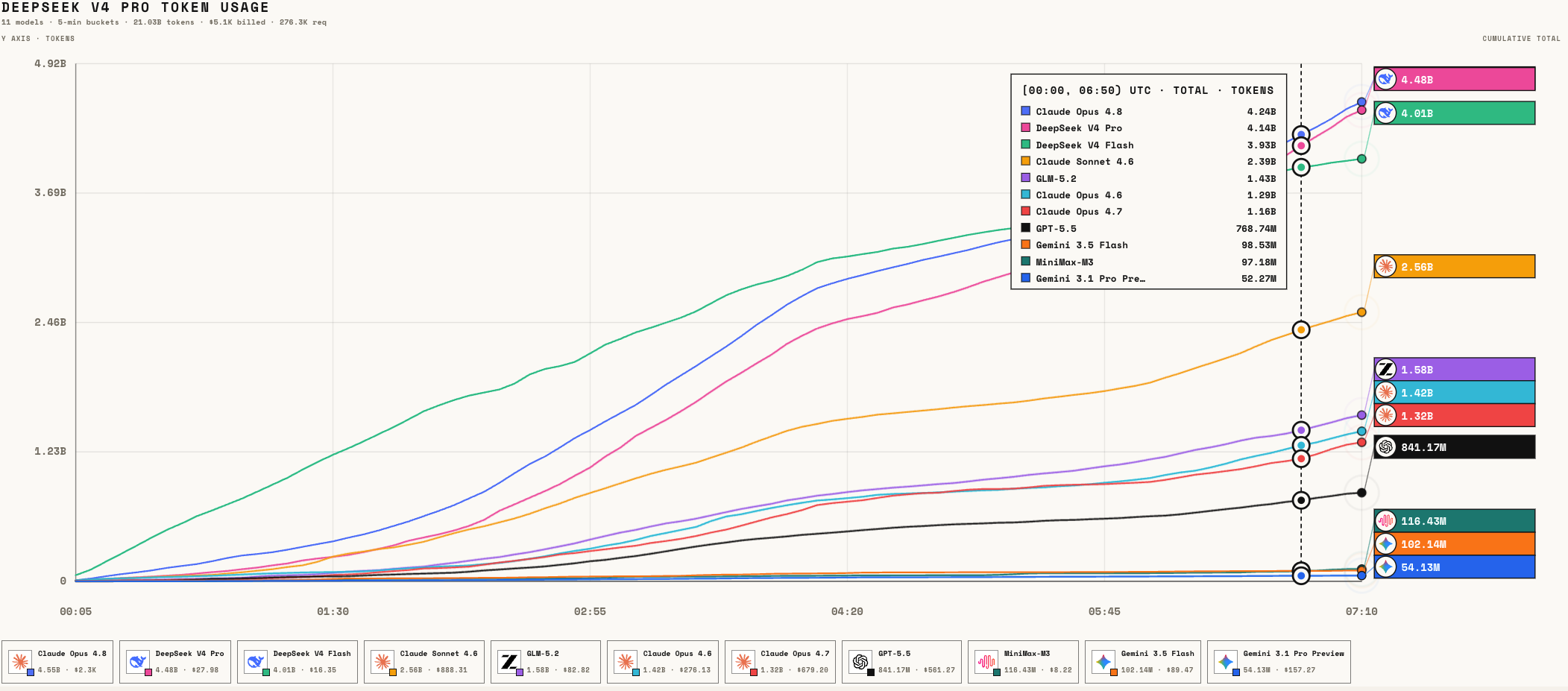
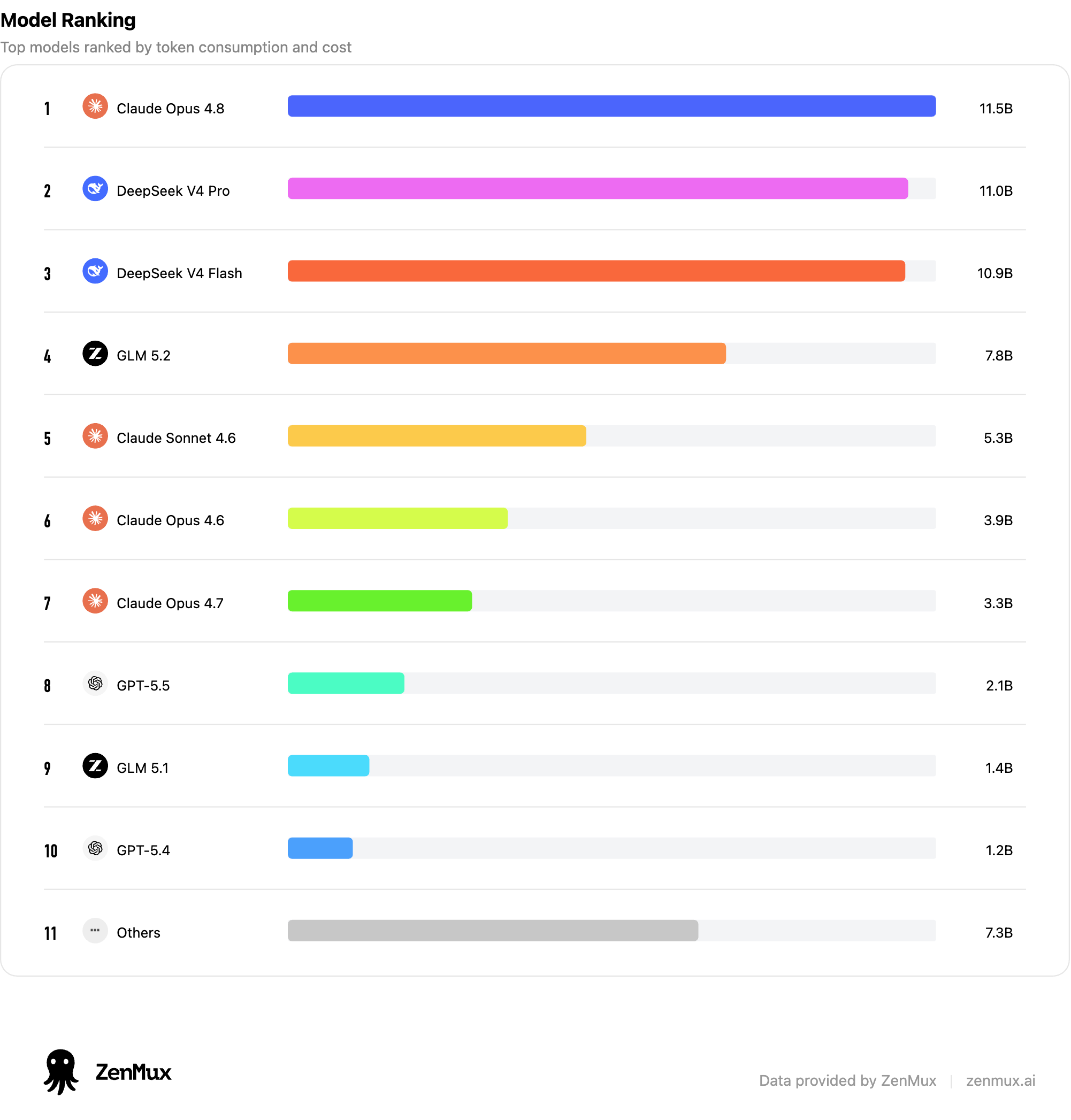
The leaderboard makes it even starker. During our observation window, Claude Opus 4.8, DeepSeek V4 Pro, and DeepSeek V4 Flash were essentially tied in the top tier — followed by GLM 5.2, Claude Sonnet 4.6, GPT-5.5, and others.
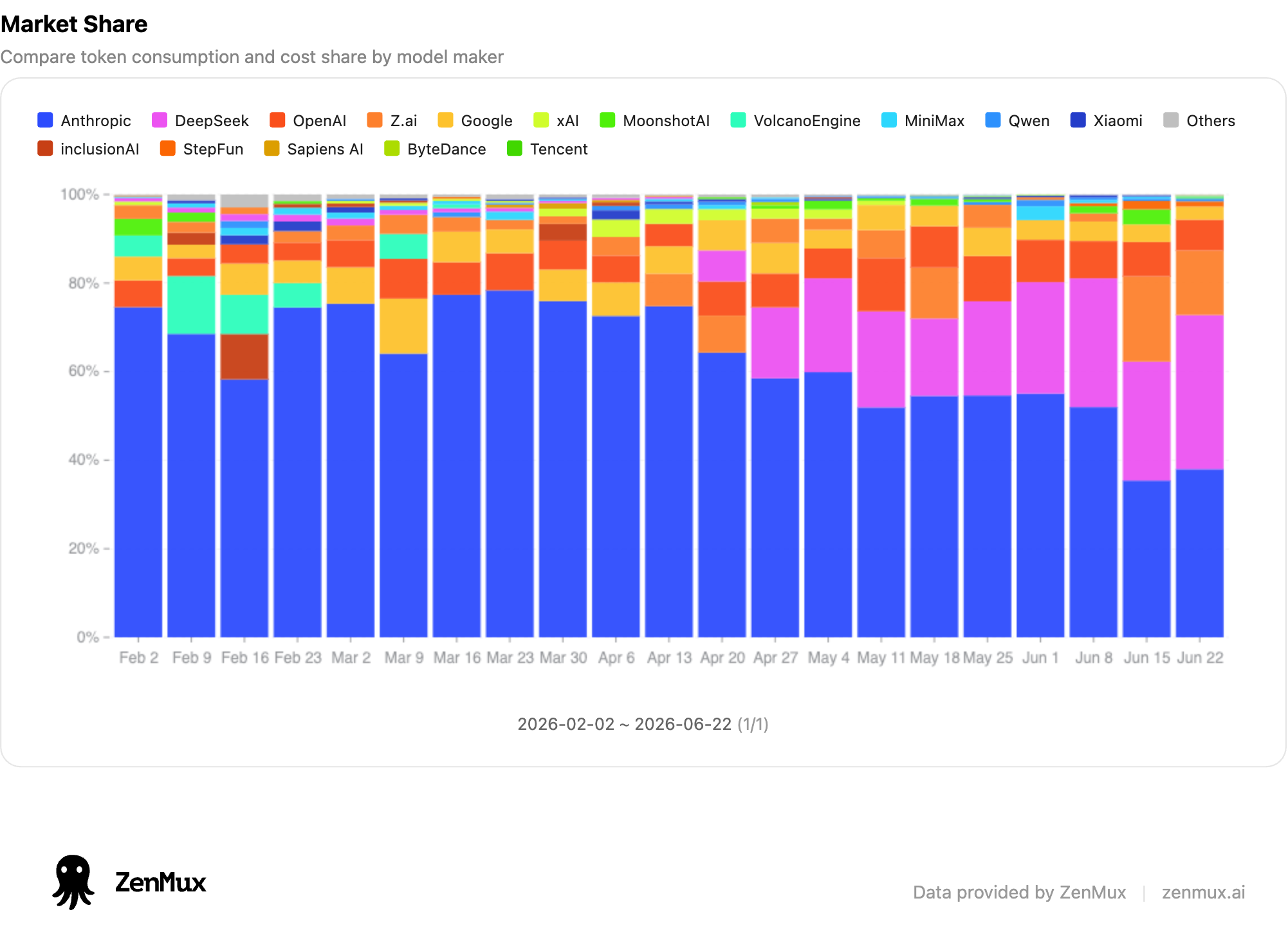
Looking at market share by provider, DeepSeek's slice of the pie has grown visibly thicker week over week. This isn't a "everyone tries the new model for a day" spike — it's steadily eating into real production workflow tokens.
Part of this is obviously that DeepSeek V4 Pro is just a very good model.
But the other part is impossible to ignore: its pricing.
DeepSeek V4 Pro is aggressively priced, and its cache hit performance is best-in-class. For coding, agents, long-context workloads — any scenario where input tokens dominate — slashing price immediately changes both how easy the model is to try, and how sustainable it is to run at scale.
We half-jokingly named this effect:
The DeepSeek Kill Line.
This doesn't mean DeepSeek is going to "kill" any other model. It means: when a model delivers acceptable performance, extremely low pricing, and stable production-grade access, it creates a new price anchor in developers' minds.
From that point on, every other model gets asked the same question:
You cost this much more than DeepSeek — are you actually worth it?
That's what makes token economics fascinating:
Launch keynotes announce who's supposed to be better. Token curves show who's actually being used.
What If Everyone Matched DeepSeek's Price?
That's the question we really wanted to answer.
What would happen if every "Eastern model" — GLM, Kimi, Qwen, MiniMax, Doubao, ERNIE, Tencent Hunyuan, Xiaomi MiMo, StepFun, Ant InclusionAI, Kuaishou KAT, and others — dropped their prices to match DeepSeek V4 Pro / DeepSeek V4 Flash?
Would developers keep choosing DeepSeek?
Or would they start experimenting at scale with GLM 5.2, Qwen3.7 Max, Kimi K2.7 Code, MiniMax M3, and today's newly released Doubao Seed 2.1 Pro, Doubao Seed 2.1 Turbo, Doubao Seed Evolving?
Even more importantly: if we track the relationship between model pricing and usage over time, can we find actual patterns in how the model market works?
That's the point of this project:
Token Economics.
We Don't Look at Benchmarks — We Look at Price and Usage
When people evaluate models, they usually talk about benchmarks, papers, launch keynotes, community sentiment, leaderboards, context window size, tool calling, reasoning ability, coding performance.
All of those matter.
But at ZenMux, we have a different, more posteriori view:
Which model do users actually spend their tokens on?
For this study, we deliberately took a posteriori approach:
We're not arguing about official benchmark scores at launch, or making assumptions about which model is "better" or "worse."
Instead, we collapse all the complex variables — model capability, PR hype, product marketing, default integrations, tool compatibility, perceived value, developer trust — down to two observable metrics:
- Price: How much does a standard call cost the user?
- Usage: How many tokens do users actually spend on this model?
Think of it as a lumped-element model.
We're not saying model capability doesn't matter. We're treating it as something the market already absorbs: if a model is genuinely good, stable, cheap, and easy to integrate, that should eventually show up in usage numbers.
First, an important caveat: this is not global market share, and it's not universal truth. This is real call data observed on the ZenMux platform. What it answers best is:
On a multi-model aggregation platform like ZenMux, which way are developers' real workflow choices flowing?
Step 1: Level the Playing Field for Usage
Comparing total cumulative usage across models is unfair.
Older models have been online longer, so they naturally accumulate more tokens; new models, even if growing fast, will look smaller on cumulative counts at first.
So we normalized usage first.
The core idea: for each model, starting from its release date, we take a 14-business-day window and calculate the typical daily token consumption during that early launch period.
In code, we use the median of workdays with actual usage (not the mean), so a single launch-day spike doesn't skew the number.
Expressed as an engineering formula:
NormalizedUsage = median(tokens used on active workdays within first 14 workdays after release)Units:
tokens / dayIntuitively, this answers:
After this model launched, roughly how many tokens did it consume on a normal workday when people were actually using it?
It's a much fairer way to compare models released at different times than total cumulative usage.
Step 2: Collapse Input and Output Pricing Into One Number
Model pricing has another quirk: input and output tokens are priced separately.
If you only look at input price, you undercount models with expensive outputs; if you only look at output price, you don't match the real token mix in coding and agent workflows.
One of ZenMux's most common use cases today is coding. We measured two typical workflows:
- Input/output token ratio for Claude Opus 4.8 in Claude Code
- Input/output token ratio for GPT-5.5 in Codex
The numbers were nearly identical: roughly 100:1 input to output.
This matches most developers' experience: AI coding isn't simple chat. It's long contexts, project files, logs, conversation history, tool results flooding in as input, with relatively short code snippets, explanations, or action suggestions as output.
So we defined a standard price basket:
100K input tokens + 1K output tokens
With input and output prices denominated in USD per 1M tokens, normalized price is:
NormalizedPrice = 0.1 × InputPrice + 0.001 × OutputPriceThis number represents the USD cost of one standard coding/agent call basket.
This step matters because in these input-heavy scenarios, input price gets amplified, while output price isn't ignored but carries a much smaller weight.
Step 3: Define Model Value as Usage / Price
With normalized daily usage and normalized price, we define a model's Value as:
Value = NormalizedUsage / NormalizedPriceUnits:
tokens / ($ · day)Intuitively, this answers:
For every $1 spent on standard calls, how much daily usage can this model carry in real workflows?
Crucially:
This is not a simple "best value for money" leaderboard.
A very cheap model that no one uses won't have high Value. A very expensive model that everyone still uses heavily can still have very strong Value.
Claude Opus 4.8 is expensive, but its real usage is enormous — so it doesn't get written off just because it costs more.
Put another way, Value isn't "cheaper is better." It's:
After price and market choice both do their work, how many tokens are users actually willing to spend on this model?
Research Limitations: Setting Boundaries First
Before we get to results, we need to be clear about the boundaries of this study.
First, ZenMux itself launched on September 28, 2024.
That means for models released before ZenMux launched, we can't fully observe their usage trajectory from day one. We do our best to normalize using the platform's observable window, but early data for older models will naturally have some distortion.
So this post is best understood as:
Observed relationships between model price and real usage on the ZenMux platform — not absolute global market share across the entire LLM industry.
Second, ZenMux is still growing.
Today's token volumes already show interesting trends, but if the platform's total token consumption grows 10x larger, samples will be thicker, noise lower, and results closer to real market structure.
In other words: this isn't a "final conclusion." It's a repeatable research methodology we'll keep running over time.
Third, this study does not separately model cache hit rates.
This is a big one.
Even if two models have identical nominal normalized prices, different cache hit rates mean developers pay different effective prices. Especially in coding, agents, and long-context scenarios, cache hit rate directly impacts real cost.
And developers care deeply about this.
Because what they actually feel isn't "the price on the pricing page" — it's:
For the same workflow, how much did my bill actually go up?
So future iterations of Token Economics will need to account not just for nominal price, but also cache hit rates, context reuse efficiency, billing differences across protocols, and how all these factors together shape developer choice.
Fourth, usage for some models may be impacted by provider product strategies.
This study counts real API call data on the ZenMux platform, but developers don't only use models through API aggregation platforms.
For example, OpenAI has been heavily promoting Codex recently, with relatively loose rate limits and generous GPT-5.5 usage quotas included in subscriptions. For heavy coding users, the marginal cost of using the official product directly can be even lower.
That means some GPT-5.5 calls that might otherwise have gone through the API are shifting to OpenAI's first-party products.
From ZenMux's perspective, this makes GPT-5.5 family observed usage lower than its real total market demand.
Put differently: the usage we observe doesn't perfectly equal total demand for a model — it's also shaped by provider product design, subscription strategies, quota policies, and developer usage paths.
For OpenAI in particular, developers dynamically switch between:
- Official ChatGPT subscriptions
- Codex
- Direct API
- Third-party aggregation platforms
So this study most accurately reflects:
Real developer choice behavior in API and multi-model aggregation scenarios — not absolute usage share for any model across the entire market.
First Look: The LLM Value Ladder
Using our Value metric, we built a ladder chart of all LLMs on the ZenMux platform:
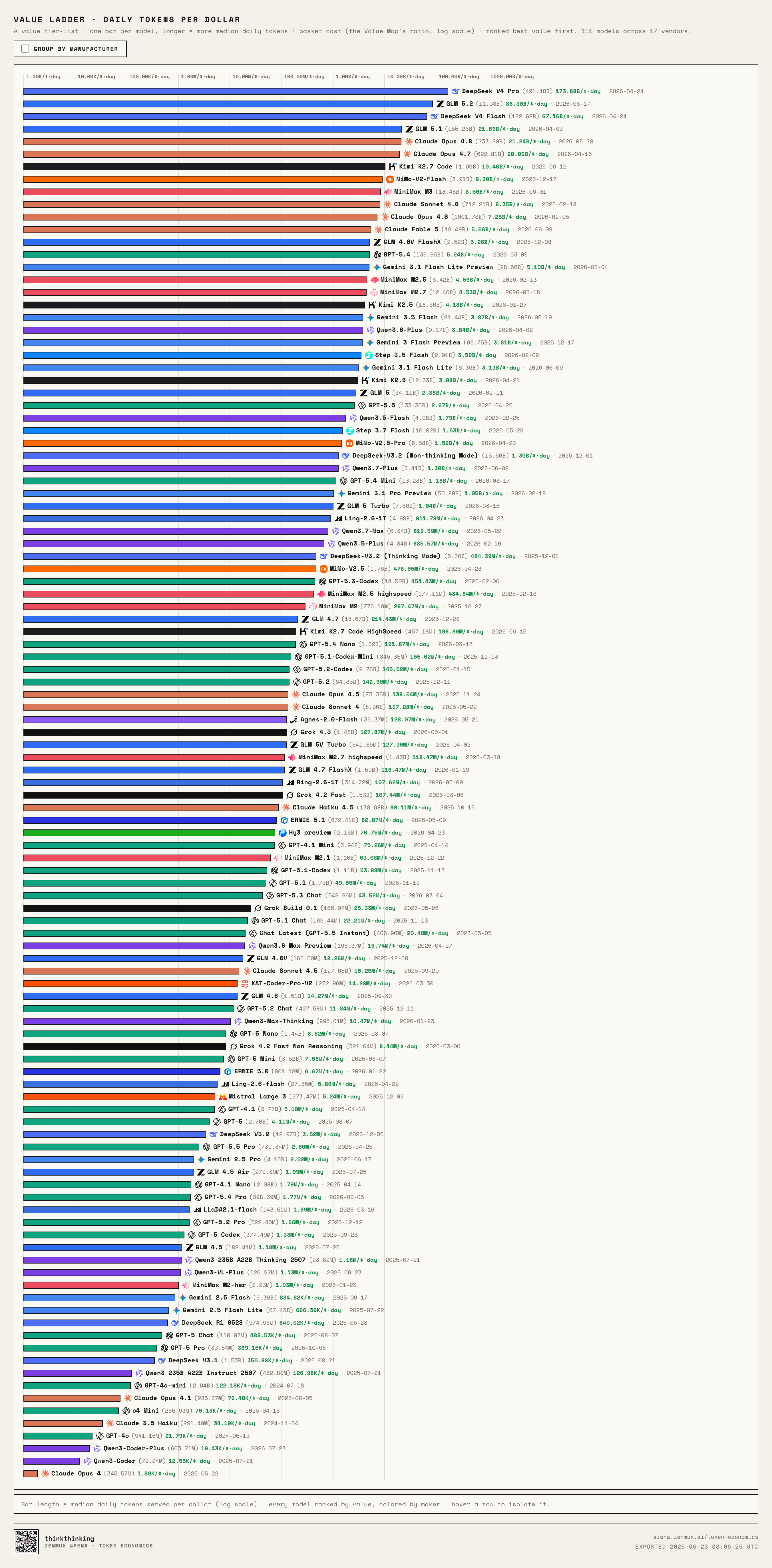
The results are fascinating.
DeepSeek V4 Pro takes the #1 spot, hands down.
That's exactly why we call it the kill line: it's not just cheap — it's capturing enormous real usage at that low normalized price point.
The second big surprise is GLM 5.2.
GLM 5.2 ranks extremely high. This isn't the polite "pretty good for a Chinese model" compliment — after accounting for both price and real usage, it's squarely in the global top tier.
Claude Opus 4.8, Claude Opus 4.7, and Claude Opus 4.6 all remain very strong.
This matters.
It proves expensive models don't get abandoned just because they cost more. As long as capability, stability, tool compatibility, and developer trust are strong enough, users will still pay.
On the flip side, many GPT, Gemini, and Qwen models land in the middle or lower tiers. That doesn't mean they're unusable — it just means that in our observation window on ZenMux, the combination of price and real consumption didn't produce the same dominant Value that DeepSeek V4 Pro did.
One personal observation:
Competition in today's model market isn't just about "who's stronger," and it isn't just about "who's cheaper." It's about who becomes the default model developers reach for again and again.
That's a mix of capability, price, and path dependence in the toolchain.
The Value Map: Four Quadrants
Rankings alone aren't enough.
So we also built a Value Map:
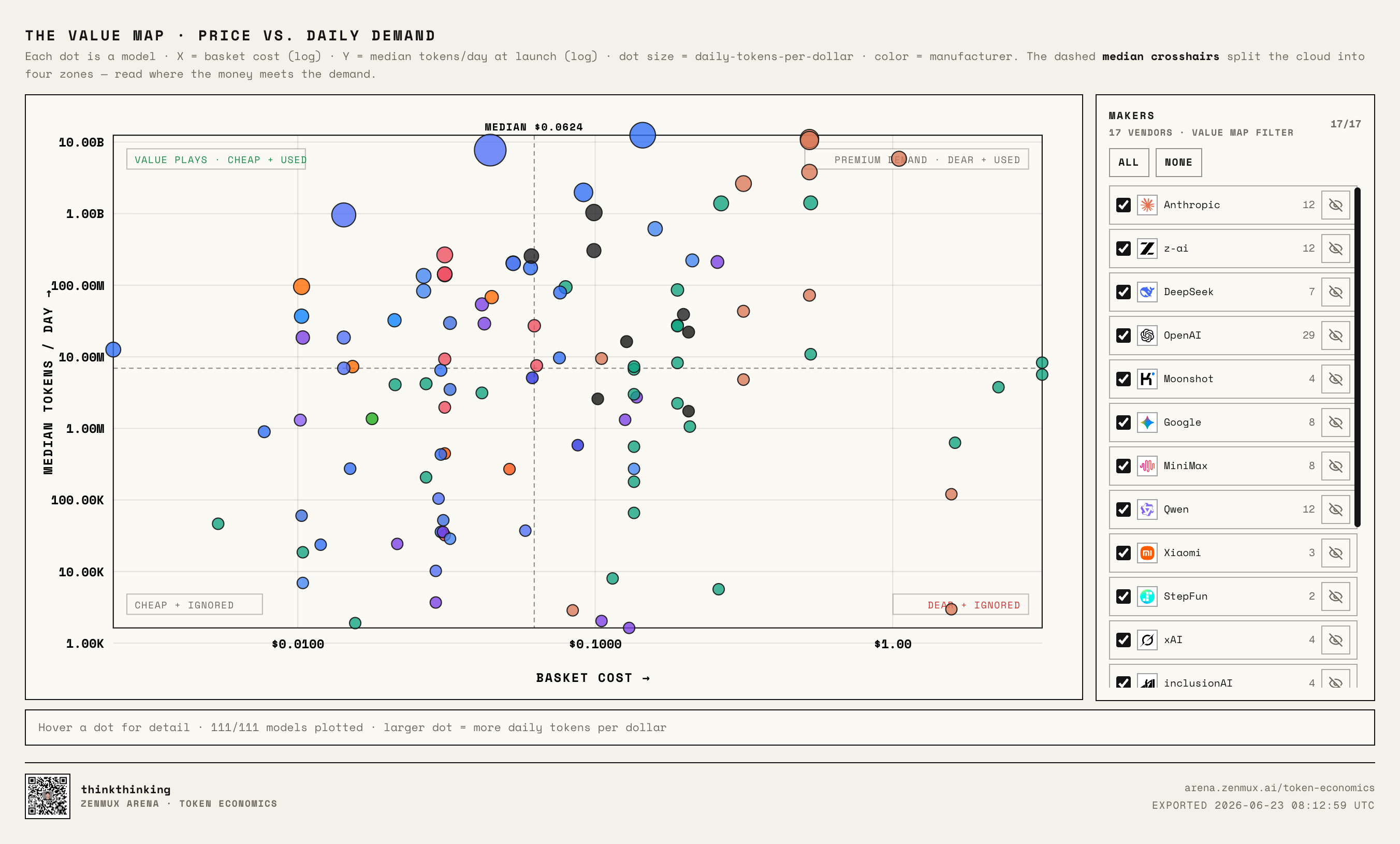
The X axis is normalized price, the Y axis is normalized daily usage.
Two dashed lines mark the median price and median usage, naturally dividing models into four quadrants:
- Low price + High usage: The real value plays
- High price + High usage: Premium demand — expensive, but users still pay
- Low price + Low usage: Cheap, but not yet being chosen at scale
- High price + Low usage: The danger zone — expensive without enough real demand to justify it
When you highlight DeepSeek, GLM, and Claude, the pattern becomes obvious:

DeepSeek V4 Pro and DeepSeek V4 Flash sit clearly in the "low price, high usage" quadrant.
GLM 5.2 is interesting: it's already broken into very high usage territory, but its pricing is no longer rock-bottom — it looks more like a Chinese model moving upmarket toward flagship premium positioning.
Claude Opus 4.8, Opus 4.7, and Opus 4.6 are classic "high price, high usage."
Claude's playbook isn't racing to the bottom on price to win scale — it's using strong model capability and developer trust to support a premium price tier.
Breaking it down by provider makes the patterns even clearer.
Anthropic: The Luxury Play, and the Market Actually Pays Up
Starting with Anthropic:
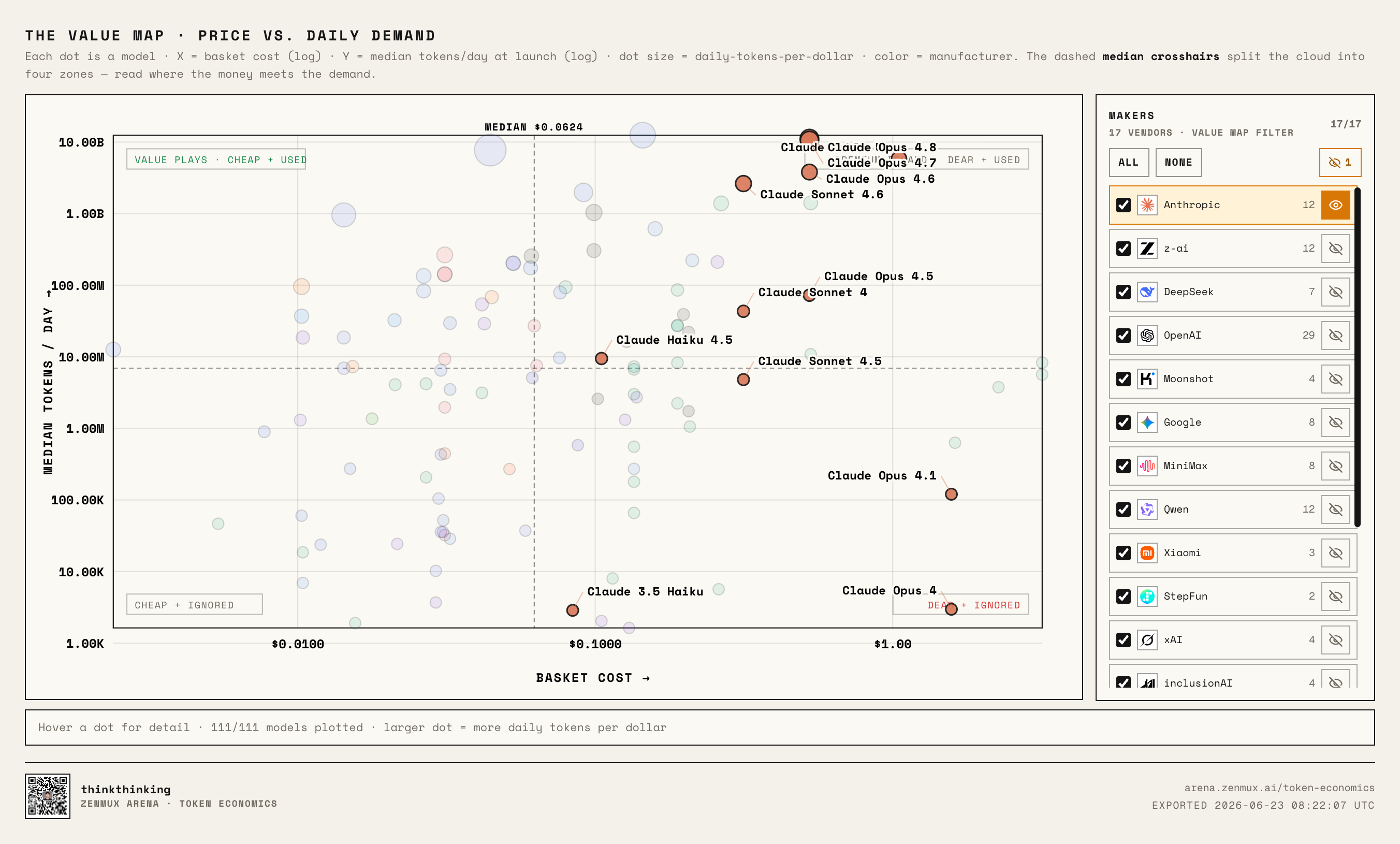
Claude has followed a luxury playbook from the start.
Most Claude models sit to the right of the median price line, especially the Opus series, firmly in high-price territory.
But the key point: they don't fall into the embarrassing "high price, low usage" quadrant.
Claude Opus 4.8, Opus 4.7, Opus 4.6, Sonnet 4.6 — all still command very high real usage.
That makes Anthropic's strategy very clear:
We're not cheap, but we're good enough that you'll still pick us for your hardest tasks.
It's why so many developers complain about Claude being expensive... but still reach for it every time they have complex coding, long tasks, or agent loops to run.
OpenAI: Covering All Bases, Drifting Toward Premium
Next, OpenAI:
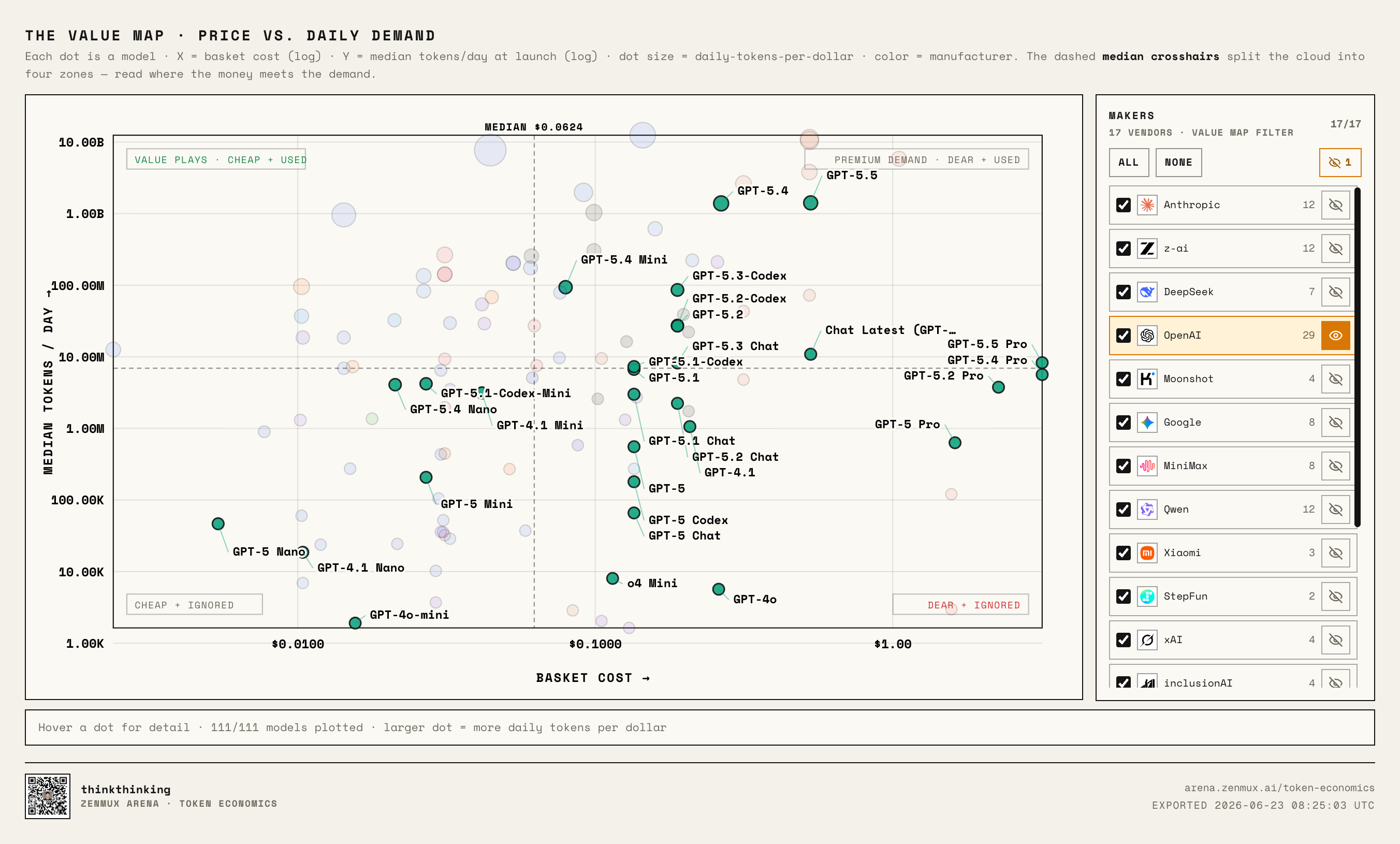
OpenAI's distribution is interesting.
Unlike Anthropic's focused strategy, OpenAI is the definition of "covering all bases": they have cheap entry-level models like GPT-5 Nano and GPT-4.1 Nano, and expensive flagships like GPT-5.5, GPT-5.4, and GPT-5 Pro.
But on the chart, cheap didn't automatically translate to high usage.
Many budget GPT models land in the bottom-left: cheap, but not seeing much real usage.
Instead, the more expensive new flagships — GPT-5.4, GPT-5.5 — are the ones moving toward Anthropic's premium demand quadrant.
This suggests OpenAI's real strategy might be shifting:
Budget models cover use cases, flagships prove the ceiling.
The catch: in ZenMux's data, cheap doesn't equal chosen. Developers still pay for "more reliable, stronger, better at coding."
Google: Clear Two-Track Strategy, and Flash Is Getting More Expensive
Next, Google Gemini:
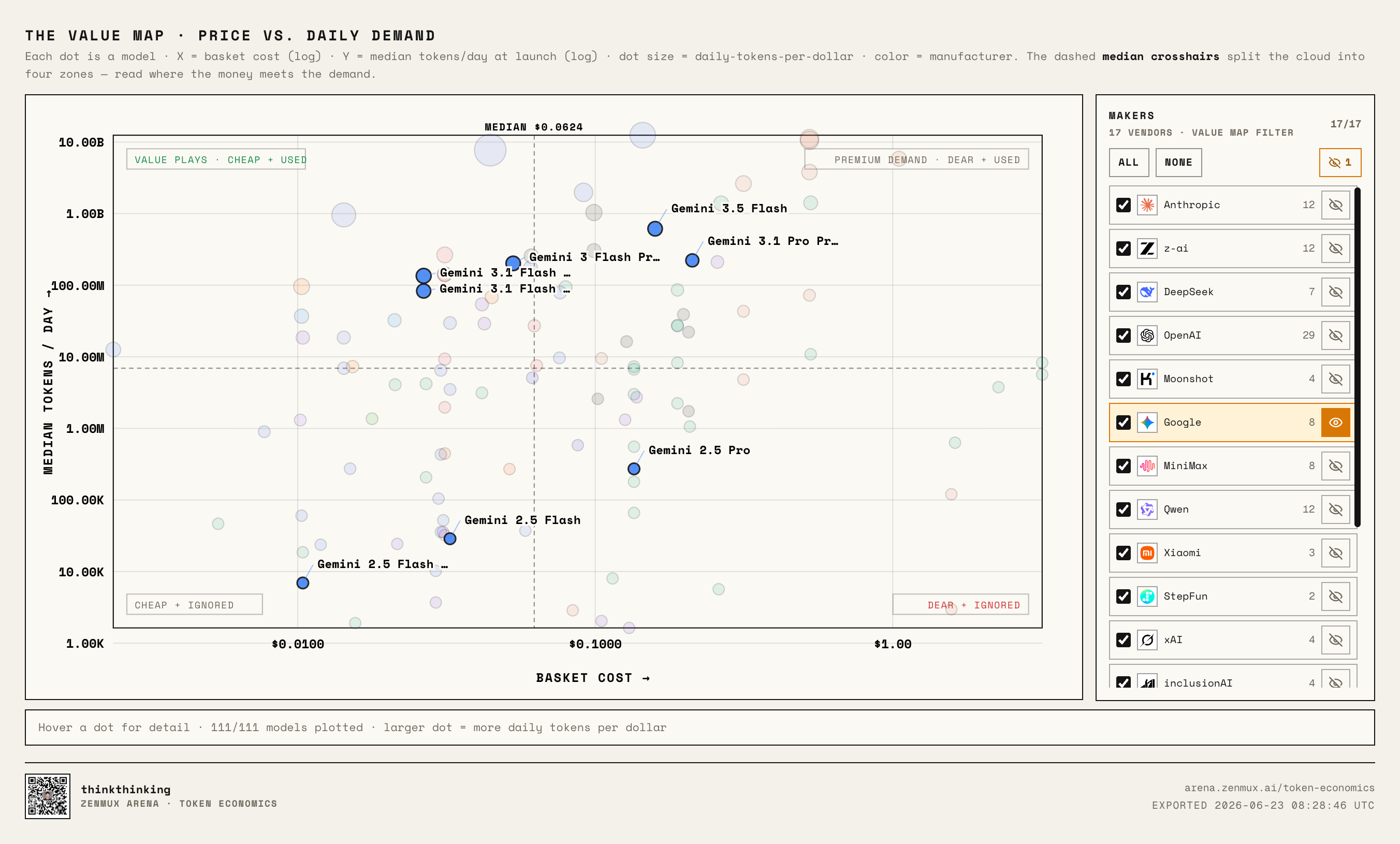
Google's strategy is relatively clear: budget Flash on one side, premium Pro on the other.
Both tracks have reasonably healthy usage — no obvious failures.
But the most notable recent trend: Gemini 3.5 Flash is no longer just the "cheap small model" — it's also moved into the higher-price, higher-usage quadrant.
This points to a hard reality:
Flagship models haven't been getting cheaper over time — if anything, the genuinely strong models are getting more confident about raising prices.
Because if a model solves real problems, the market will give it pricing room.
DeepSeek: This Is the Kill Line
Then there's DeepSeek:
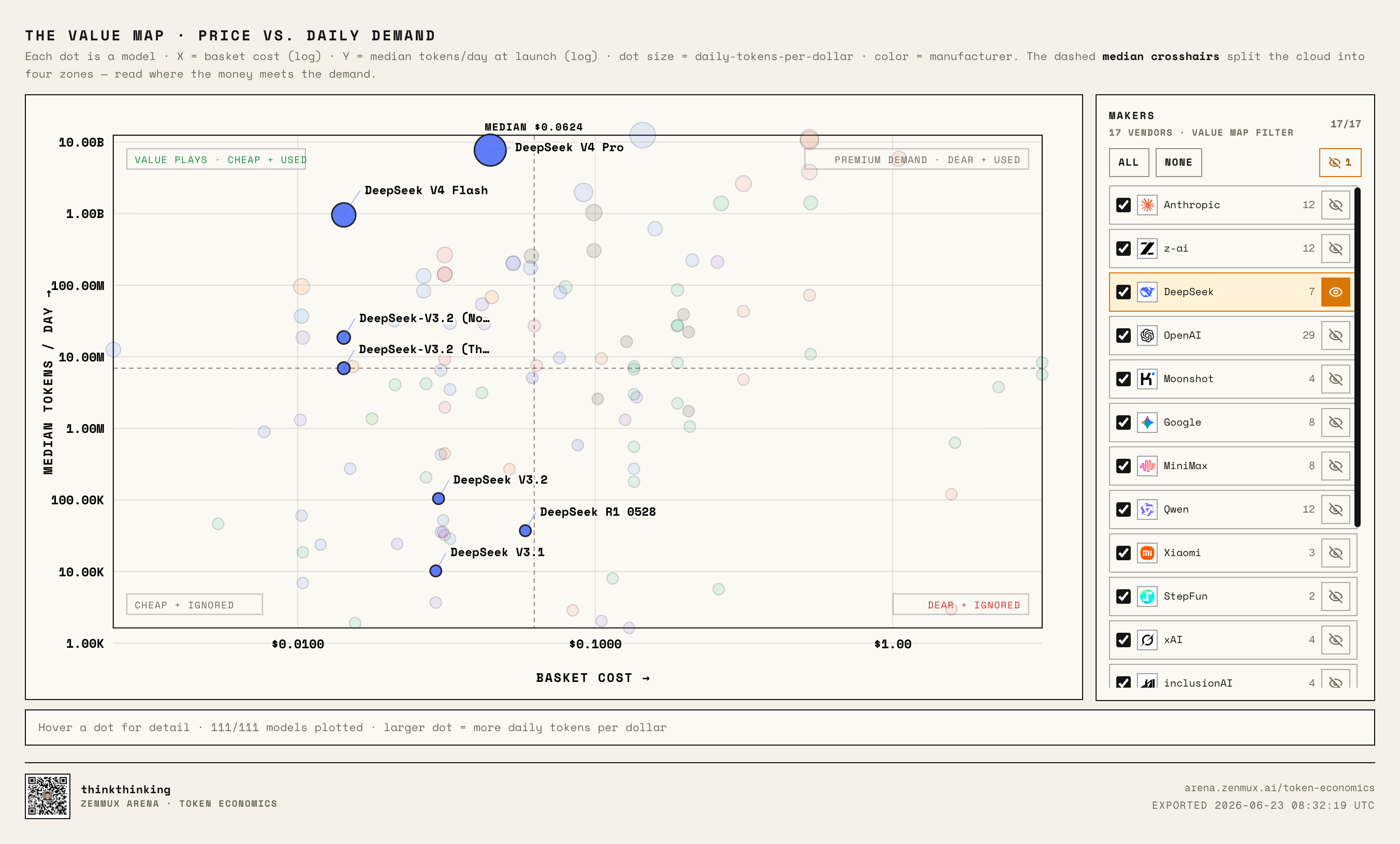
DeepSeek's strategy from V3 to V4 has been crystal clear: low price, strong performance, high availability.
DeepSeek V4 Pro and DeepSeek V4 Flash are textbook examples of "low price, high usage."
The scariest part isn't that they're cheap — it's that when they're this cheap, people actually want to use them.
That's very different from the many "cheap but nobody cares" models out there.
So the real meaning of the DeepSeek Kill Line is this:
When a model simultaneously delivers low price, strong performance, stability, and scalability, it pulls the entire market's price reference point downward.
From that point on, every other model's pricing has to answer:
I'm more expensive than DeepSeek — what exactly am I offering that justifies it?
Zhipu GLM: The Chinese Path That Looks More and More Like OpenAI
Next, Zhipu GLM — especially when placed side by side with OpenAI:
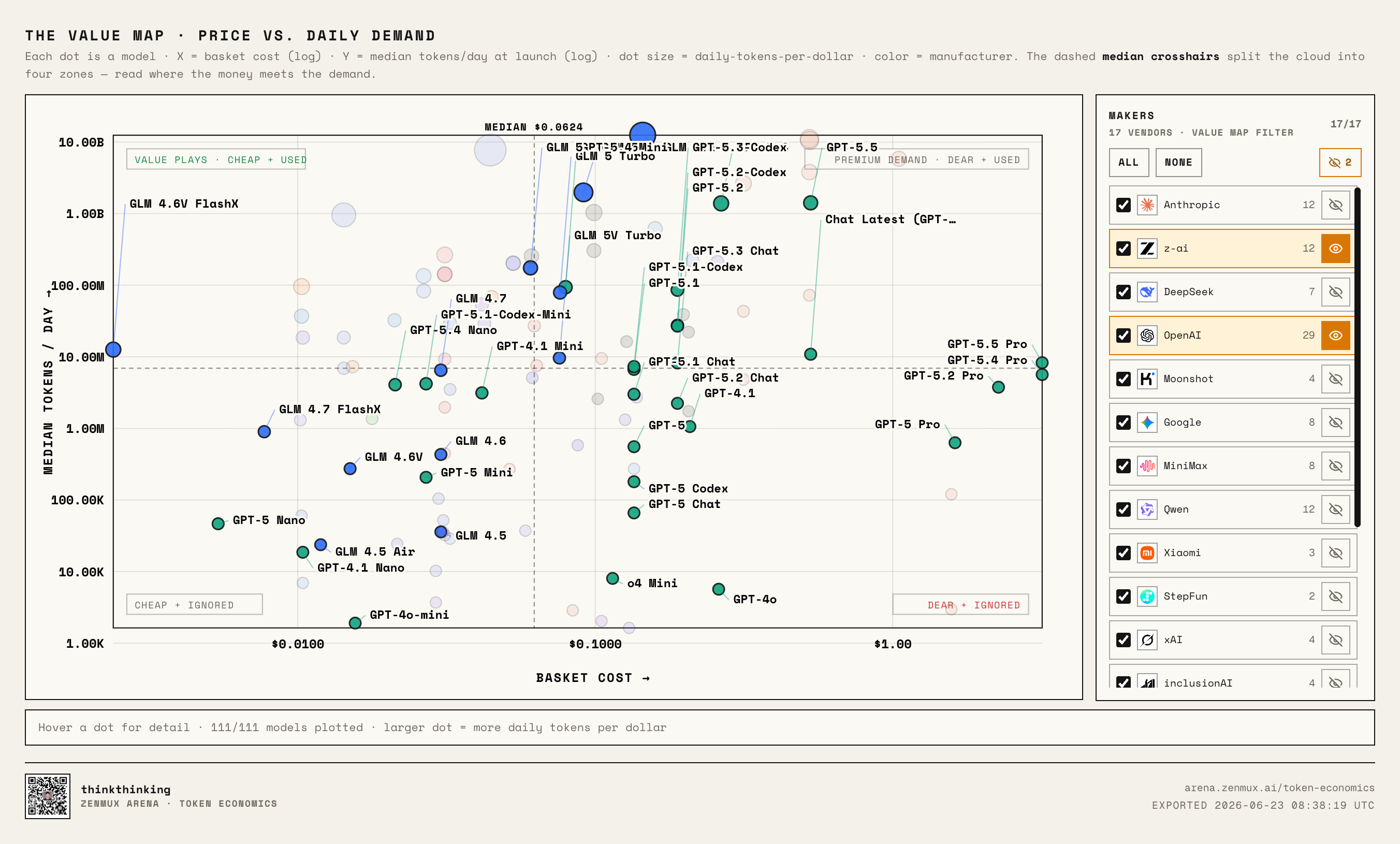
People say Zhipu is the Chinese company that most resembles OpenAI.
From a token economics perspective, that observation actually holds up.
GLM's product line shows a similar two-track strategy: budget Flash / Turbo models on one side, and the more premium flagship GLM 5.2 on the other.
Some of their earlier budget-focused models didn't break out, but GLM 5.2 is a different story.
It's no longer playing the "Chinese model = cheap alternative" narrative — it's moving into "high-usage flagship model" territory.
This could be an important inflection point for Chinese models:
People used to explain Chinese models' success with "they're cheap." Going forward, the models that actually break out will have to make users willing to pay even when they're not cheap.
The Rest: Kimi, MiniMax, Qwen
Kimi looks like it's positioning against Anthropic:
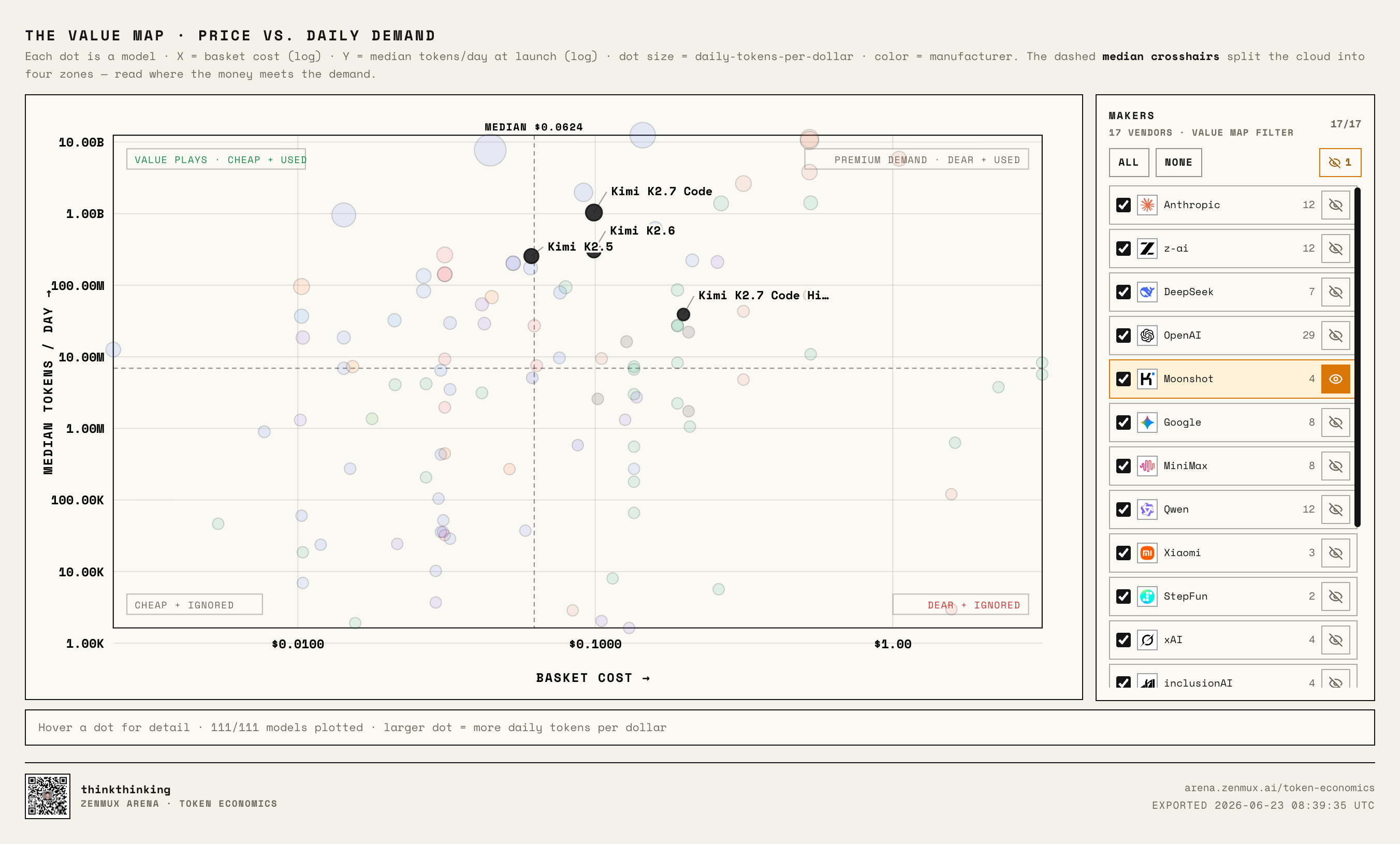
It's not racing to the bottom on price, leaning more premium. Kimi K2.7 Code shows solid usage, which means developers have real interest in its coding capabilities.
MiniMax looks more like it's positioning against DeepSeek:
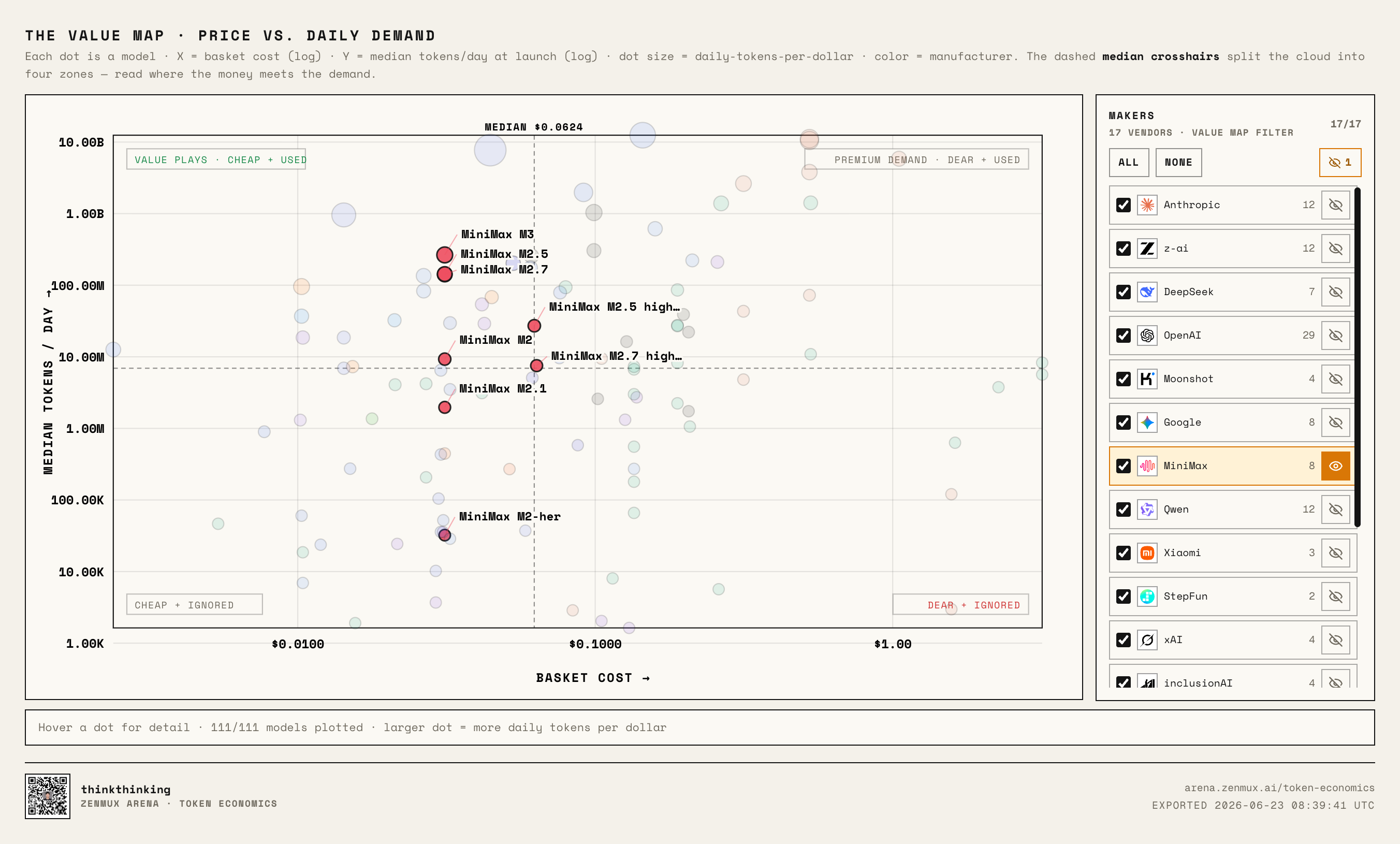
Mass-market positioning, affordable pricing. If models in this category can keep growing real usage, they have real potential.
Qwen has the most scattered distribution:
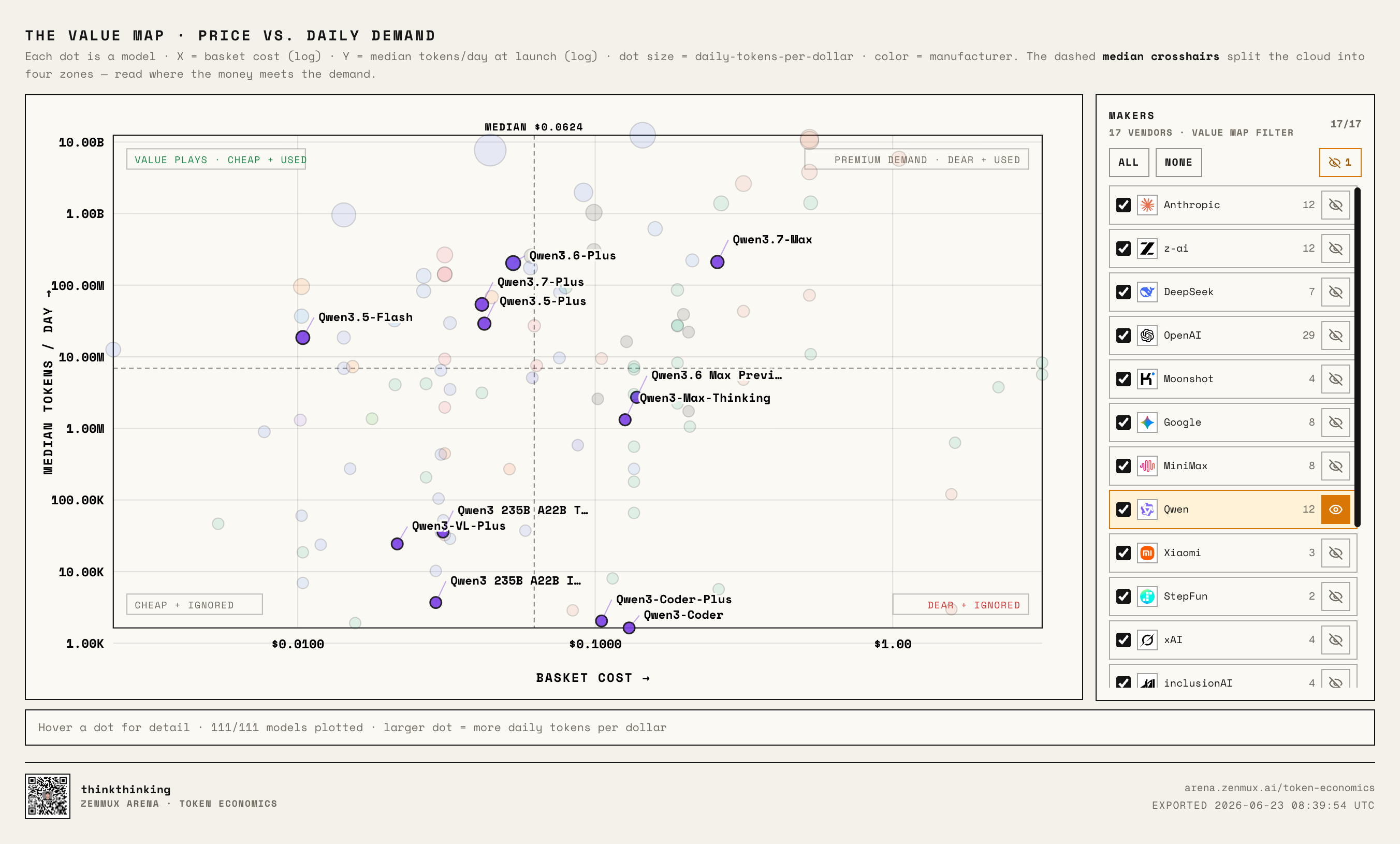
They have models in almost every quadrant.
That means very broad product line coverage, but from the outside, the strategy also looks less focused.
That said, the latest Qwen3.7 Max is worth watching: it's moving upmarket toward premium, and market reception is decent.
This reinforces a broader trend:
Chinese model providers can't win on cheap forever. The real deciding factor is whether any of them can land in the "high price + high usage" quadrant.
So We're Running the DeepSeek Kill Line Challenge
Since the question was sitting right there, we decided to run an actual experiment.
We priced a full batch of "Eastern models" down to match DeepSeek V4 Pro or DeepSeek V4 Flash using our normalized pricing methodology.
In other words: we threw all these models into a fairer, harsher arena:
Price can't scare users away anymore. We just watch who actually keeps the tokens.
The full model list comes from this config in our open-source repo:
config/token-economics-live-models.jsonModels in the challenge:
- DeepSeek V4 Pro
- DeepSeek V4 Flash
- GLM 5.2
- Kimi K2.7 Code
- Qwen3.7-Plus
- Qwen3.7-Max
- MiniMax M3
- Step 3.7 Flash
- Agnes-2.0-Flash
- ERNIE 5.1
- Ring-2.6-1T
- Ling-2.6-1T
- Hy3 preview
- MiMo-V2.5
- MiMo-V2.5-Pro
- Ling-2.6-flash
- KAT-Coder-Pro-V2
- Qwen3.6 Flash
- Doubao Seed 2.1 Pro
- Doubao Seed 2.1 Turbo
- Doubao Seed Evolving
Models already priced below the kill line (like Agnes-2.0-Flash and Ling-2.6-flash) stay at their original prices.
Some of the flagship discounts are dramatic:
| Model | Anchor | Normalized Price Change | Discount |
|---|---|---|---|
| Qwen3.7 Max | DeepSeek V4 Pro | 0.2575 → 0.04437 | 82.8% |
| GLM 5.2 | DeepSeek V4 Pro | 0.1444 → 0.04437 | 69.3% |
| Qwen3.7 Plus | DeepSeek V4 Flash | 0.0416 → 0.01428 | 65.7% |
| Kimi K2.7 Code | DeepSeek V4 Pro | 0.0990 → 0.04437 | 55.2% |
| MiniMax M3 | DeepSeek V4 Flash | 0.0312 → 0.01428 | 54.2% |
| KAT-Coder-Pro-V2 | DeepSeek V4 Flash | 0.0312 → 0.01428 | 54.2% |
| Ring-2.6-1T / Ling-2.6-1T | DeepSeek V4 Flash | 0.0325 → 0.01428 | 56.1% |
The rules are simple:
- If a model's normalized price is higher than DeepSeek V4 Pro, discount it down to DeepSeek V4 Pro
- If a model's normalized price is below DeepSeek V4 Pro but above DeepSeek V4 Flash, discount it down to DeepSeek V4 Flash
- If a model is already cheaper than DeepSeek V4 Flash, leave it as-is
Our goal is straightforward:
Flatten the price variable as much as possible, then watch who real developers actually choose.
Live Leaderboard: Who Crosses the Kill Line?
We built a live leaderboard for the challenge:
https://arena.zenmux.ai/token-economics?view=live
It supports real-time and cumulative views, and you can toggle between Token and Cost perspectives.
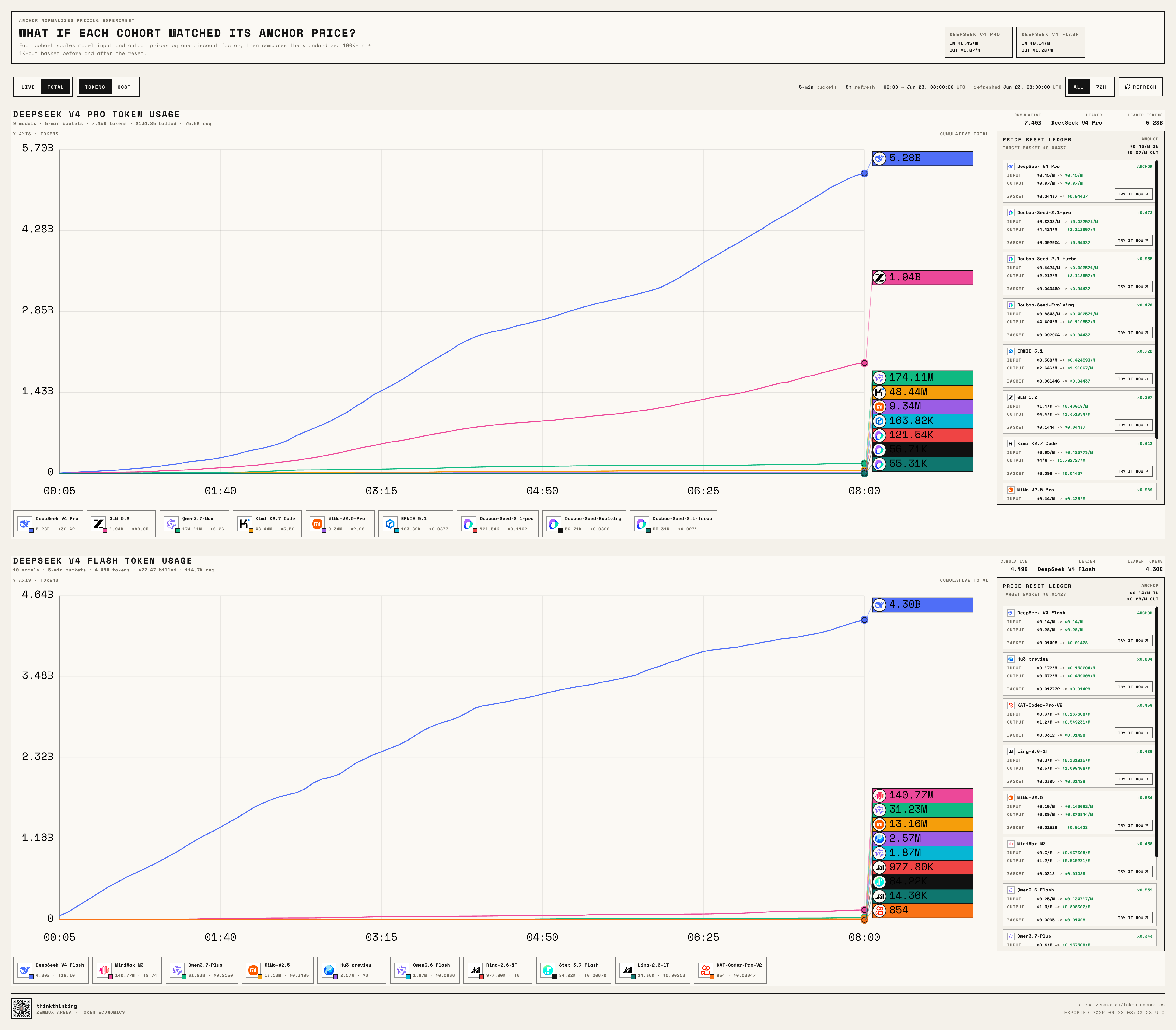
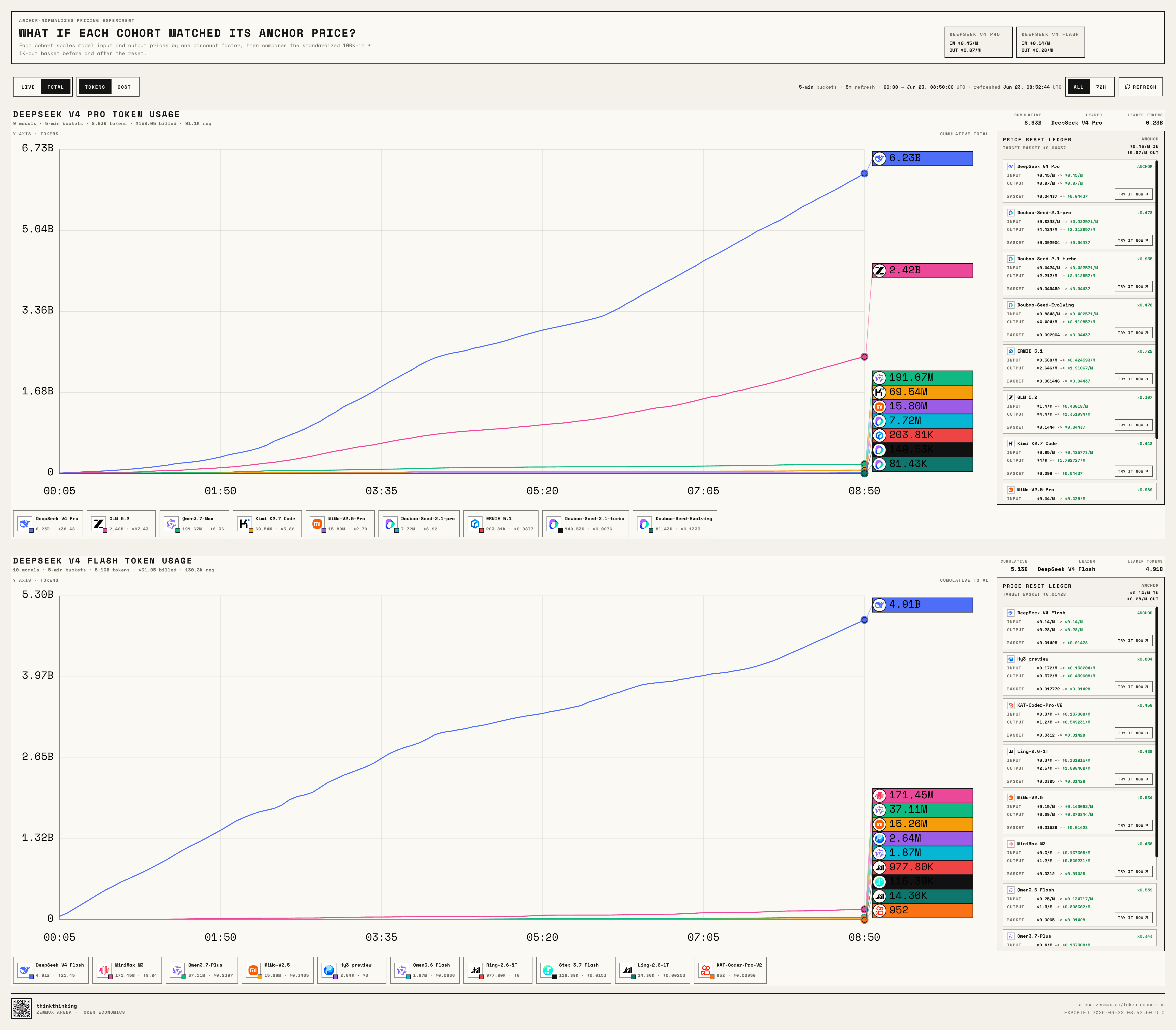
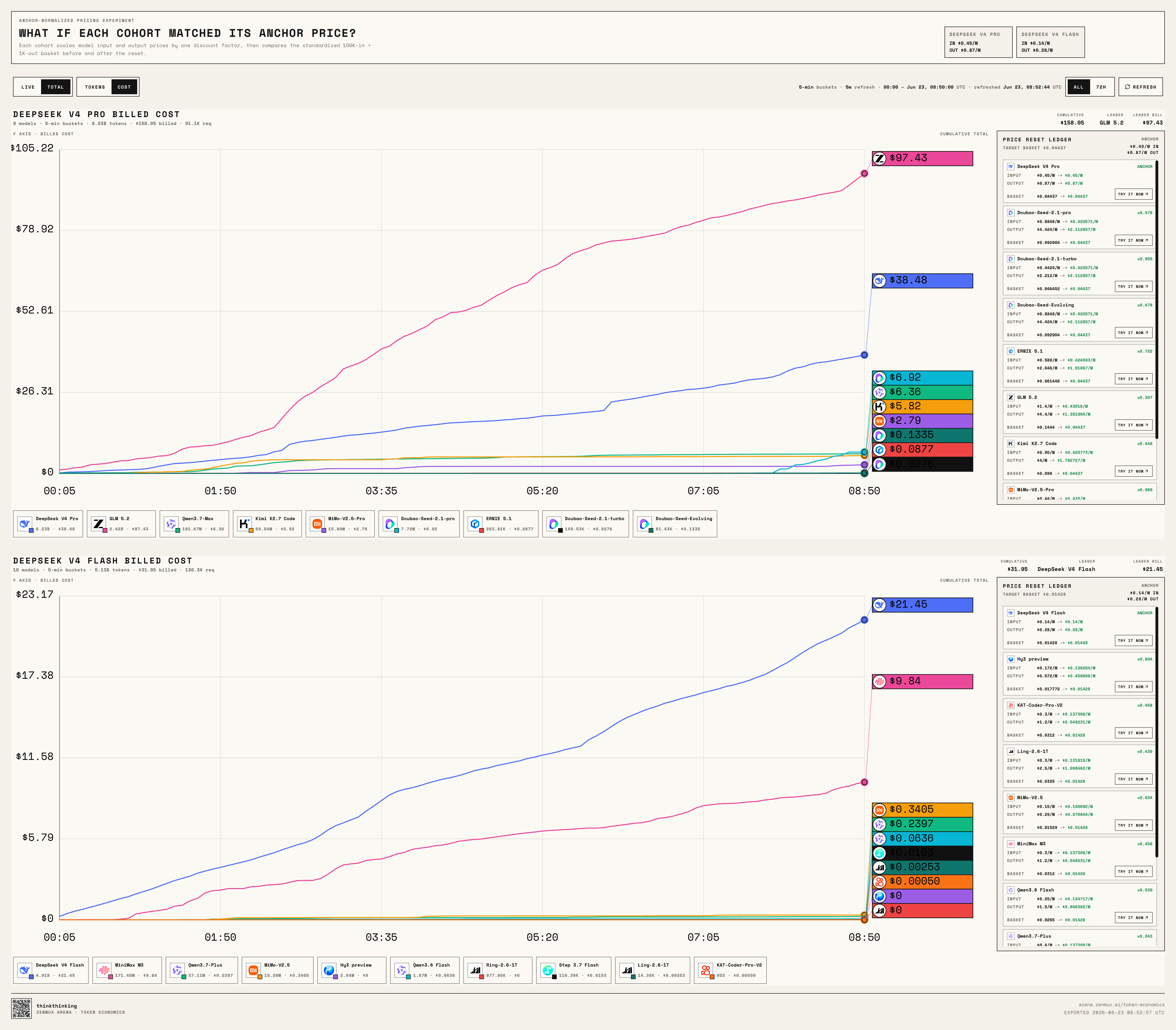
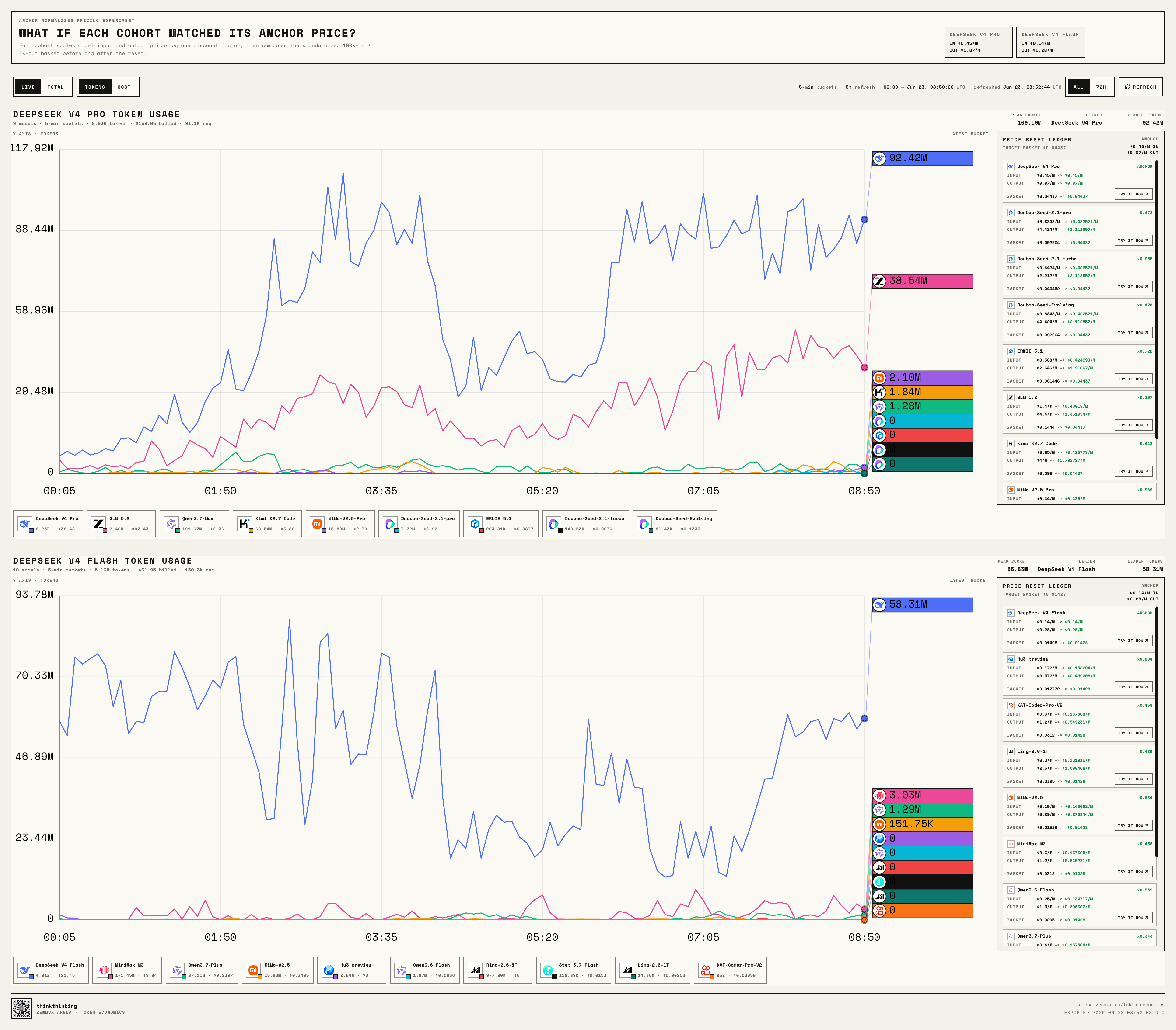
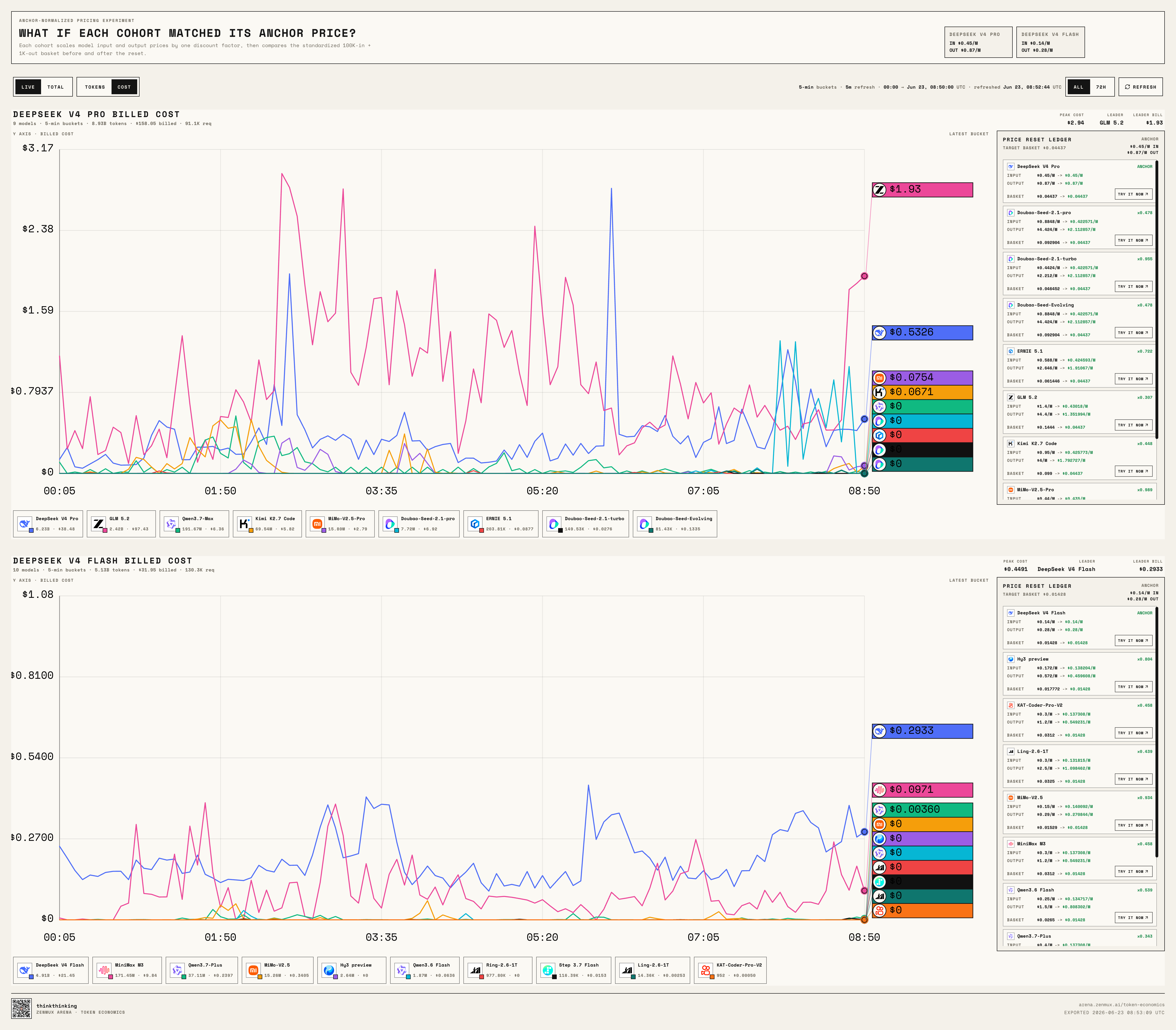
Think of it as a continuously running model market experiment:
When DeepSeek V4 Pro, DeepSeek V4 Flash, GLM 5.2, Kimi K2.7 Code, Qwen3.7 Max, MiniMax M3, Doubao Seed 2.1 Pro, Doubao Seed 2.1 Turbo, Doubao Seed Evolving, and the rest are all sitting at roughly the same price point, who actually gets called by developers?
The answer won't come from launch keynotes.
The answer will come from the token curves.
Because in the model market, the most honest vote isn't a like or a benchmark screenshot — it's the tokens developers actually spend real money on, every single day.
A More Realistic Conclusion
After running this Token Economics research, my biggest takeaway is this:
Model pricing isn't just a finance number.
It's a combined statement from a model provider about their capabilities, costs, ecosystem position, and market ambition.
Cheap is the entry ticket — not a free pass.
If a low-price model can't generate real usage, that means it only cut prices — it didn't win users over.
If a high-price model keeps getting heavy usage, that means the market knows it's expensive... and is still willing to pay for its certainty, capability ceiling, and production stability.
So maybe the harshest truth in the model market is:
Price is the label providers put on a model. Usage is the vote users cast with their money.
And a model like DeepSeek V4 Pro, which delivers both low price and high usage, becomes something bigger: a new pricing regime.
It's not just a model — it's a new reference line.
That reference line forces every model provider to answer three questions:
Are you going to take Claude's premium path, and prove you're worth the higher price? Are you going to take DeepSeek's kill line path, and price so aggressively developers can't say no? Or can you do what GLM 5.2 is doing, break out of the "Chinese model = cheap alternative" narrative, and become a legitimate flagship option?
That's the Token Economics we'll keep tracking going forward.
We don't just care what models say about how good they are. We care who developers actually spend their tokens on.
Come Test the DeepSeek Kill Line
For the Kill Line Challenge, ZenMux has already discounted all the models above using our unified normalized pricing strategy.
Both PAYG (pay-as-you-go) and subscriptions are priced accordingly.
All models on the ZenMux platform natively support:
- OpenAI Chat Completions protocol
- OpenAI Responses protocol
- Anthropic Messages protocol
You can plug them into Claude Code, Codex, OpenCode, OpenClaw, Hermes, and other agent tools — mix, match, and test freely.
Interactive Value Map: https://arena.zenmux.ai/token-economics?view=value
Live challenge leaderboard: https://arena.zenmux.ai/token-economics?view=live
The project is open source: https://github.com/ZenMux/zenmux-arena
We're going to keep watching this:
When prices are leveled, who still keeps the real usage?
That might be closer to the real answer about the model market than any leaderboard.
Because leaderboards answer "who looks strongest on paper." Token Economics asks a harder question:
Who is worth calling, again and again?
If you found this useful, feel free to share, like, save, or open issues in the repo to discuss.
I'm thinkthinking — Ideas Worth Spreading!